|
I am a final year Ph.D. Candidate focusing on Computer Vision at the Center for Research in Computer Vision at University of Central Florida. My research is advised by Prof. Mubarak Shah. Previously, I completed my Bachelor of Technology (B.Tech) and Master of Technology (M. Tech) degrees at IIT Kanpur. My Masters thesis was supervised by Dr Vinay Namboodiri.
Email: mail [at] rohitg [dot] xyz |

|
|
Within the broad field of computer vision, I am particularly interested in applying LLMs for vision, multi-modal vision, and generalizable self-supervised learning. My Ph.D. research focuses on novel approaches in multi-modal video understanding by bridging text and vision. My Masters thesis was focused on automated generation of video descriptions. |
|
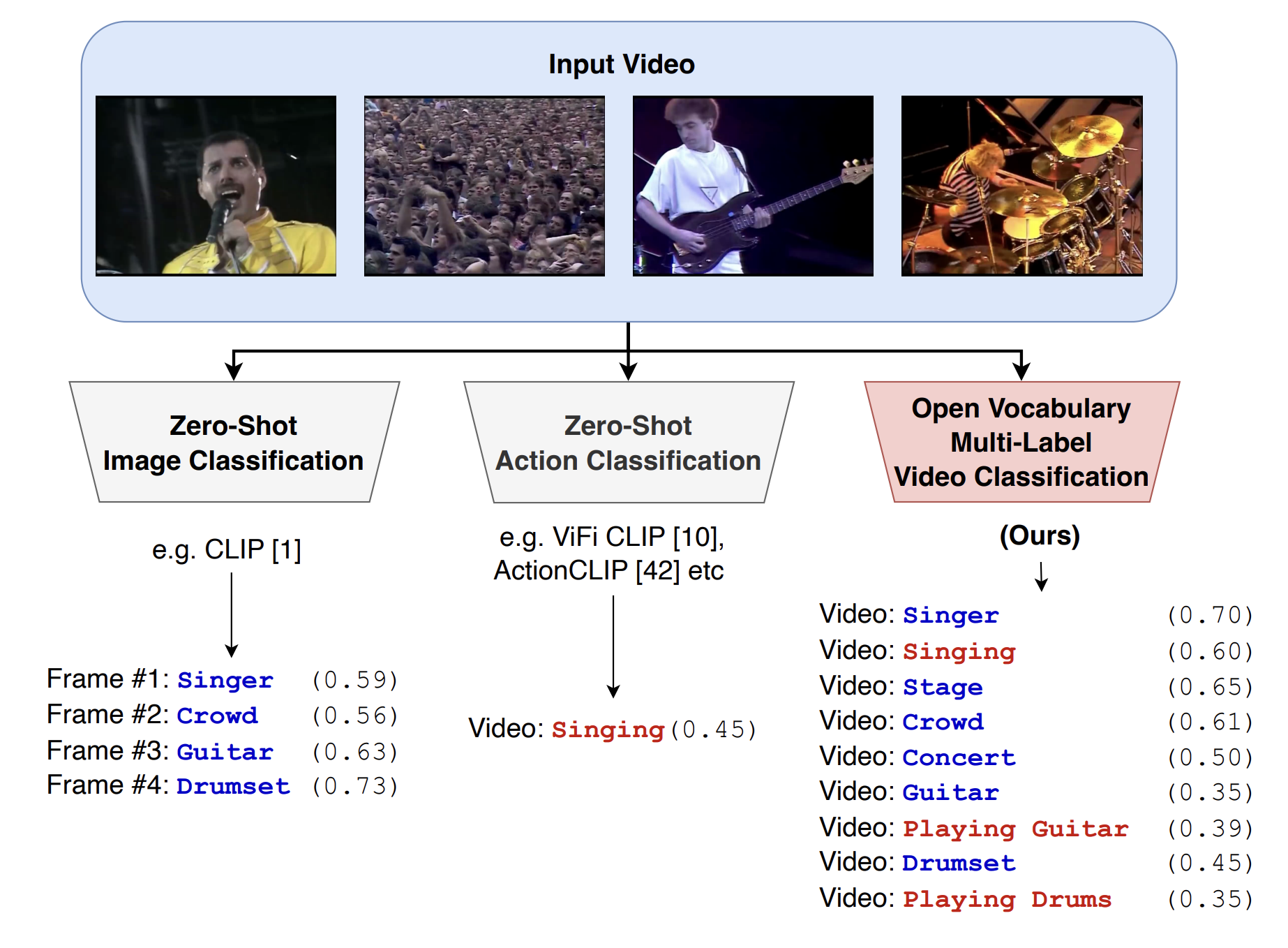
Rohit Gupta, Mamshad Nayeem Rizve, Ashish Tawari, Jayakrishnan Unnikrishnan, Son Tran, Mubarak Shah (ECCV 2024) Paper / We propose an approach for open vocabulary multi-label video classification that adapts a pre-trained vision-language model, such as CLIP, to simultaneously recognize multiple actions and entities in videos without exhaustive labeled data. Our method employs a large language model to generate soft semantic attributes for novel class labels, enhances temporal modeling in the vision encoder, and leverages synthetic labels from unlabeled video data. Experiments across diverse datasets demonstrate strong zero-shot classification performance, advancing holistic video understanding. |
|
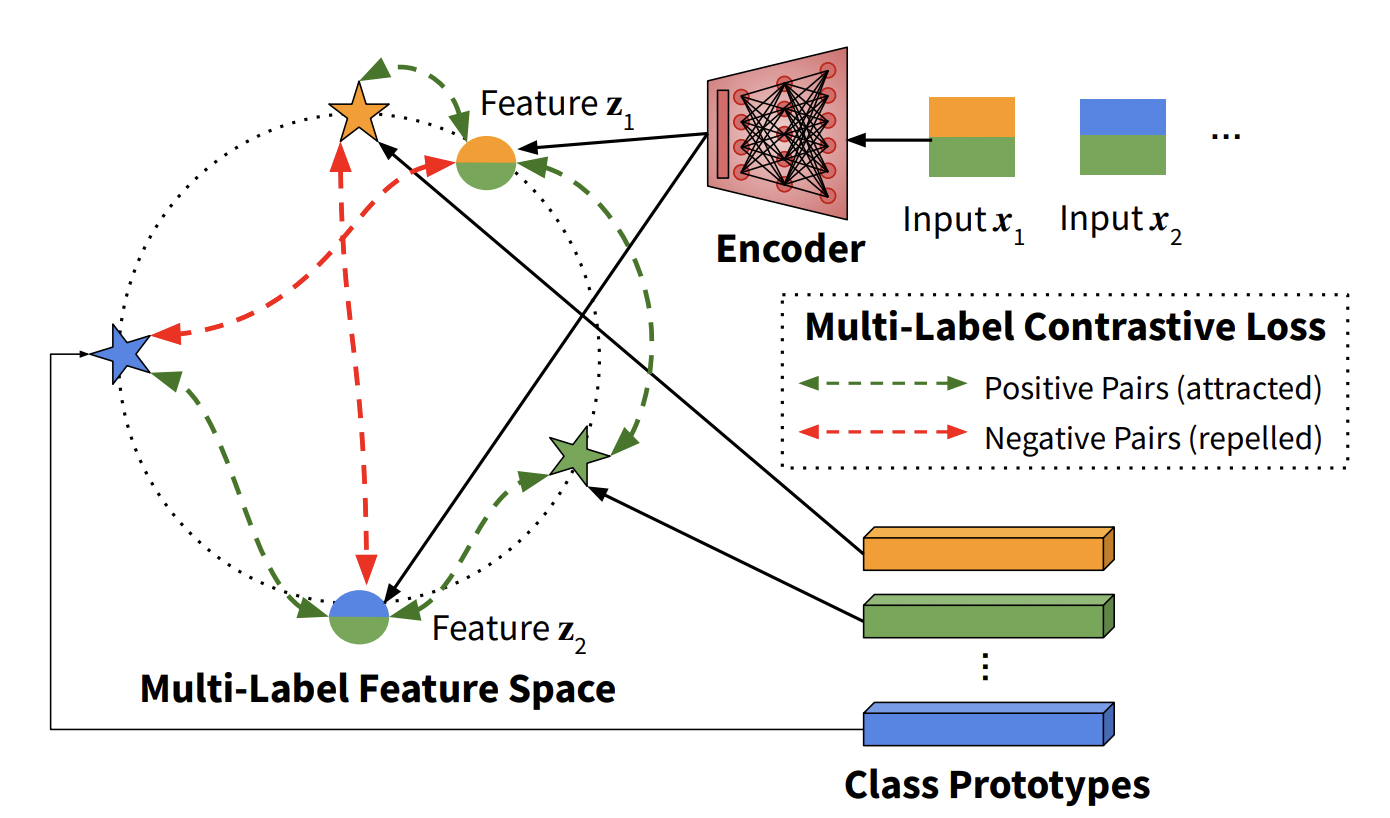
Rohit Gupta, Anirban Roy, Sujeong Kim, Claire Christensen, ..., Ajay Divakaran, Mubarak Shah CVPR, 2023 Paper / Dataset We propose Class Prototype Contrastive Learning to solve two key problems associated with practical Fine-grained Video Classification: (a) Multi-Label nature of training data (b) Fusing information effectively across modalities. Our method achieves strong results on the COIN and YouTube-8M datasets, and we also propose a novel video dataset from the education domain with expert annotated labels, and designed such that understanding both video and speech is essential for effective classification. |
|
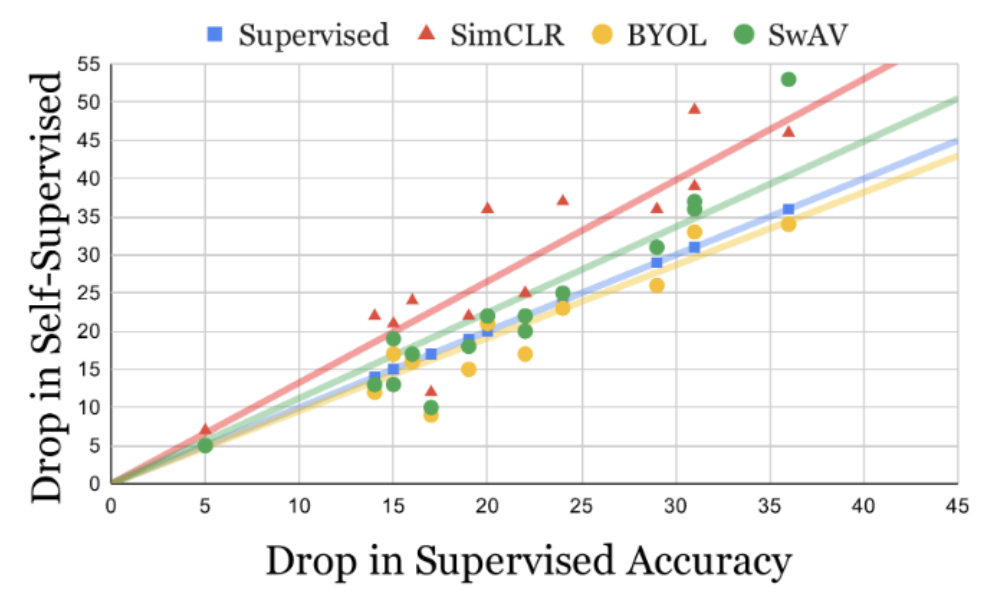
Rohit Gupta, Naveed Akhtar, Ajmal Mian, Mubarak Shah AAAI, 2023 arXiv / Paper Contrastive Self-Supervised Learning (CSL) results in significantly lower adversarial robustness than supervised learning, even while achieving similar accuracy on clean data. We establish this through extensive experiments and provide evidence to suggest that the lower robustness is caused by presence of false negative pairs during CSL training. |
|
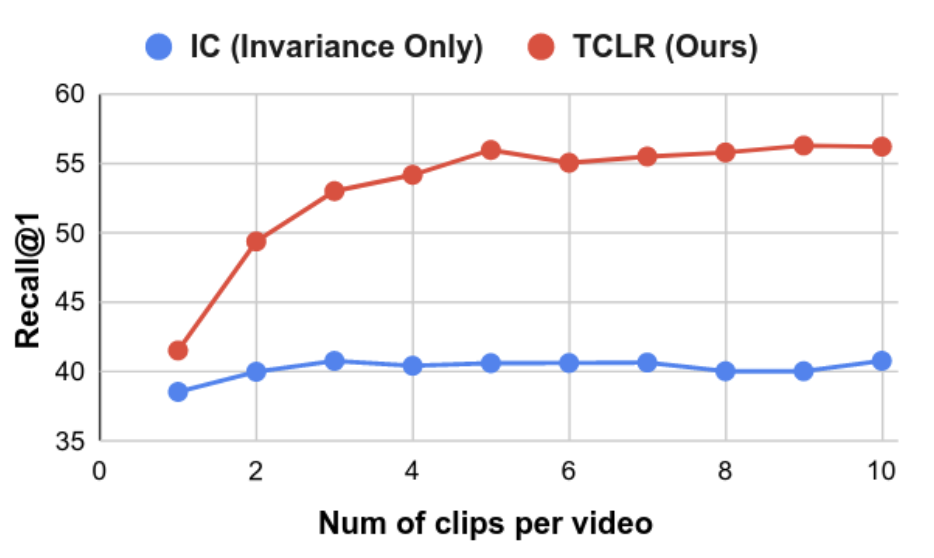
Ishan Dave, Rohit Gupta, Mamshad Nayeem Rizve, Mubarak Shah CVIU 219, June 2022 arXiv / code Unlike images, videos contain significant temporal variation in motion and appearance. Hence simple extensions of Contrastive Self-Supervised Learning (CSL) to videos fail to capture temporal distinctiveness in the representation. We propose Temporal Contrastive Losses and learn temporally distinct representations and achieve significant gains on downstream video tasks. |

|
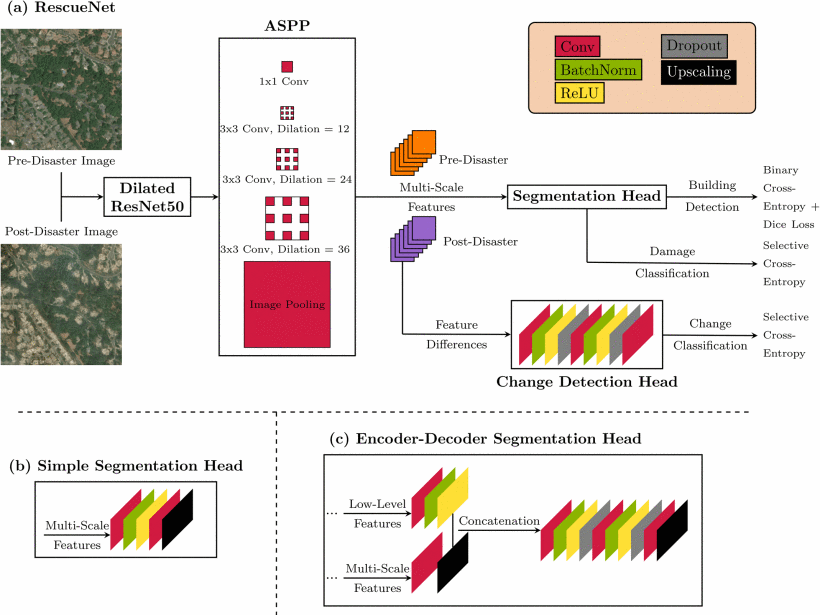
Rohit Gupta, Mubarak Shah ICPR 2020 arXiv / Paper Accurate building damage assessment is crucial for effective Humanitarian Aid and Disaster Response (HADR) after natural disasters. Satellite and UAV imagery, often with computer vision, has been used for this task. Existing methods follow a two-stage approach—building detection and damage classification—which limits performance. We propose RescueNet, a unified, end-to-end trainable model that simultaneously segments buildings and assesses damage levels. To address the problem’s complexity, we introduce a localization-aware loss function combining Binary Cross Entropy for segmentation and a selective Categorical Cross-Entropy for classification. Tested on the large-scale xBD dataset, RescueNet outperforms existing methods, achieving better accuracy and generalization across regions and disaster types. |
|
|
Reviewer, CVPR 2025
Reviewer, ICLR 2025 Reviewer, ECCV 2024 Reviewer, CVPR 2024 Reviewer, ICCV 2023 Reviewer, CVPR 2023 Reviewer, AAAI 2023 Reviewer, ECCV 2022 Reviewer, IEEE Journals: Neural Netw. Learn. Syst., Circuits Syst. Video Technol. Mentor, NSF REU 2020 and 2022 |
|
|
SB-Bench: Stereotype Bias Benchmark for Large Multimodal Models
Self-Supervision is Not All You Need: In Defense of Semi-Supervised Learning |
|
Reports |
"Knights": First Place Submission for VIPriors21
Action Recognition Challenge at ICCV 2021
Hindi-English Parallel Corpus Generation from Comparable Corpora for Neural Machine Translation Video Description by Learning to Detect Visual Tags |
|
Built upon Jon Barron's template. |